视频 - AK的 LLM 普及课
发布于2月6日,安德烈·卡帕西最新AI普及课:深入探索像ChatGPT这样的大语言模型|Andrej Karpathy
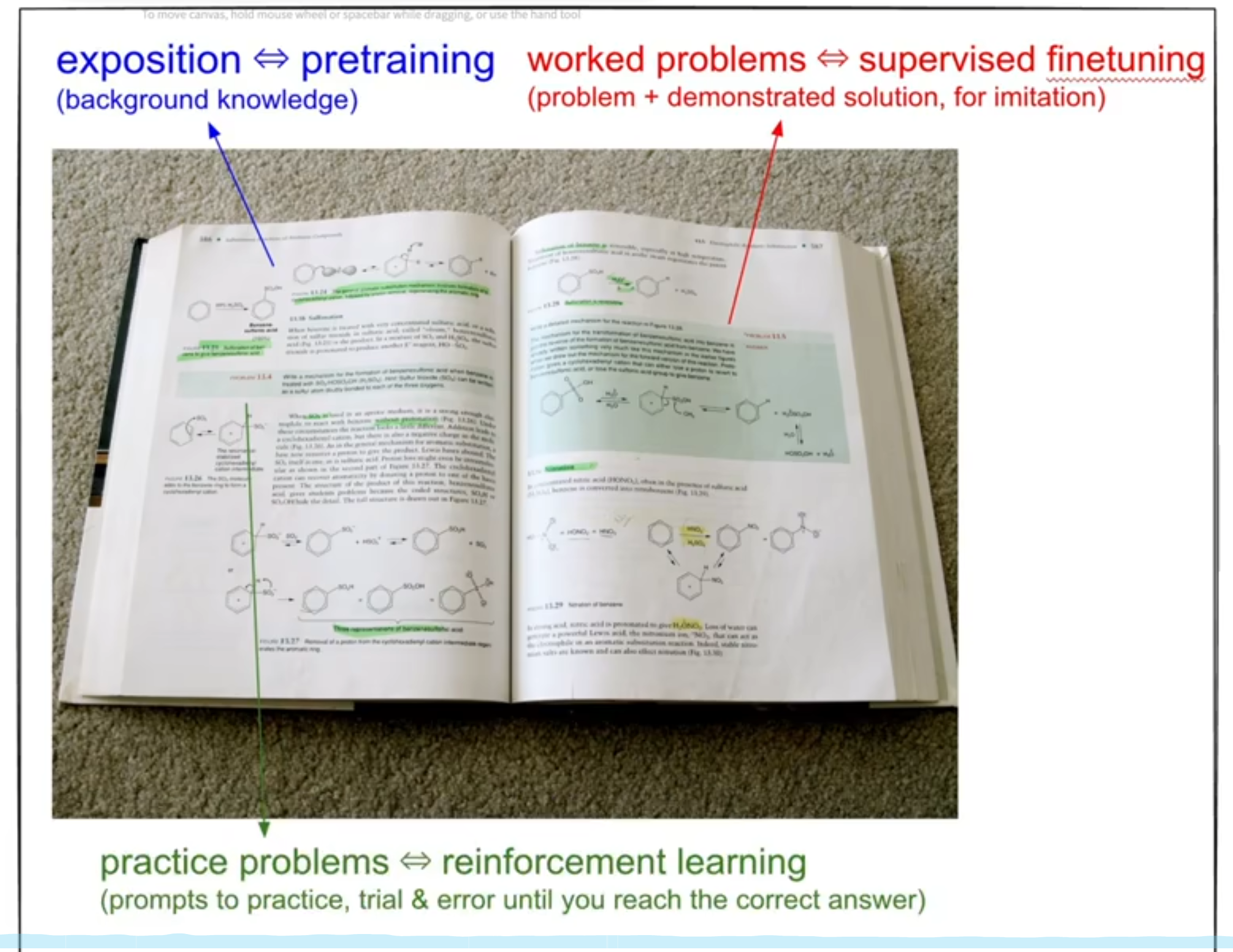
1.Pre-train阶段
把预训练的405B个参数视为一种互联网所有信息的压缩。
预训练得出基础模型,base model,互联网文档模拟器,internet document simulator,总归是一个下一个词元的预测器,next token prediction。
2.SFT阶段
预训练pre-training约需要三个月,耗费数百万美金,post-training需要时间短,约三小时。
后训练创建的对话数据集远比互联网的文本数据集要小得多。
一切只是令牌序列 token sequences,一维令牌序列 one dimensional token sequence,
要知道在post-training中,SFT需要的对话数据集,需要专业的人工打标。
参与创建这些对话数据集的人类标注着通常是有教育背景的专家。
向GPT提问时,返回的内容与训练集的内容在统计上是相关的,大致而言,它是来自于统计上模仿人类标注者的东西。只是有预训练的超大规模文本数据/世界知识,的加成,所以回答能让人满意,相当于模型里面藏了各种各样的专家,主要就是这个极其庞大的世界知识库。
消除幻觉的两种方式:第一种,加入否定数据集,模型就会了解并有机会学习将这种知识基础的拒绝与其网络中某个内部神经元联系起来。第二种,创建一种搜索数据集,放入几千个例子,模型将能够很好地理解这个工具的工作原理。
这么看来,后训练中数据集的处理,让模型能针对某个特性进行进一步的提升,anthropic的文学能力,代码能力,不知道经过了什么样的后训练进行提高呢?
不要把一堆问题,堆到一个词元token里面,把问题分散开,分成一个个小问题,让下一个词元正确的概率提高。因为单个词元的计算步数有限,尽量不在一个词元做完整的预测,一步一步来解决。这应该就是一些提示词工程的作用。不过慢慢在后训练的数据集中做优化,效果越来越好。针对性的大量减少幻觉,但是幻觉还是会存在。
它是一个非常神奇的随机系统,不能完全信任它。归根到底是一个概率预测下一个词元的机器,只是用了很多巧妙的方法,让效果变强,由于参数足够大,能够相信知识能蕴含在里面。
模型看不到字符,只能看到token,计数不好,善用工具。
3.强化学习阶段
强化学习阶段就像把大模型送进学校,进行学习,然后在某方面变得特别优秀。pre-train就像了解背景知识,基础知识;SFT就像专家告诉我们怎么解决一个问题,让我们了解解题步骤;RL就像做很多习题提高。
纯RL,只对结果进行判断,让模型自己判断那个结果好,选择优秀的解答,尝试-奖励。不过针对答案是确定唯一的可验证领域verifiable domains这样效果才好。在无法准确验证的领域,使用了RLHF(reinforcement learning from human feedback),通过训练一个神经网络(人类模拟器),去对模型的回答结果进行打分,然后优化权重。
RLHF不是RL,而是某种FT方式,因为训练次数多了之后,有可能会出现离谱的答案,称为对抗样本adversarial examples,导致SFT模型运行几百次RLHF后,必须裁剪它,结束这个过程,不能过度运行这个奖励模型,因为优化过程将开始操纵它,(模型会适应这个奖励模型?)。在可以验证的领域verifiable domains可以无限运行RL,才能发挥RL的那种“魔力”。
4.未来
我们可以对音频、图片、视频,都进行同样的处理,序列化tokenize,大量数据预训练、STF,生成“多模态助手”。
长期代理任务。
一切将变得更普遍和隐形more pervasive and invisible,这就像是无处不在,融入工具中integrated into the tools and in everywhere。
5.总结
ChatGPT的回答答案,是对OpenAI数据标注者的神经网络模拟。
RL发展出的思维策略是否能够转移,仍然是一个开放的问题。在可验证领域
domains that are verifiable中出现的思考过程是否能够迁移,并在不可验证的其他领域(例如创意写作中)具备普遍性,这种转移发生的程度在该领域仍然是未知的。所有我们不确定是否能够在所有可验证的事物上进行强化学习,并看到在像这个思考提示,在那些不可验证的事情上获益。
另一个有趣的事情是,这里的强化学习仍然是新的、原始和幼稚的。仅看到了推理问题刚刚展现最开始的闪光,希望看到一些在原则上类似第37步的事情不在围棋游戏中,而在开放领域的思维和问题解决中发生。原则上,这种范式能够做一些非常酷、新奇和令人兴奋的事情,甚至是以前没有人想到的事情。
takeaway:
更理解这几个阶段,和模型的回答为何如此有魔力,本质上是next token prediction,不过做了很多和人类回答思维接近的优化,加上超大规模的文本学习和压缩,知识被压进了模型了,有了世界知识的概念。后面做很多处理,去把这些知识引导出来。通过后期SFT、RLHF,以及现在的纯RL。有方式能让模型针对性地学会某个东西,像不存在信息的判断,和搜索模式的引导。
RL能否在不可验证领域发光发热还有待观察,看第37步会不会在开放领域出现。
看似简单的算法背后,有很复杂的程序实现和工程优化,数据的处理也是很复杂的。
知道了具体的原理后,要思考模型的应用,怎么变得更普遍和隐形,无处不在,融入工具中。
我还是有个念想,做一个领域知识自动更新的街区,让人在里面wander,这里面的知识更有条理,模型调控里面的内容。不过世界上的知识太多了,怎么抓住这个有用的脉络?头大。不求完整,但求自动?A knowledge neighborhood based on AI agent.