视频字幕生成、提取软件部署
发布于 , 最后编辑于运行
运行程序
运行图形化界面版本(GUI)
python gui.py
运行命令行版本(CLI)
python ./backend/main.py
后面可能需要提取一些视频文案,刚好前几天看到一个推荐对视频字幕进行操作的几个仓库( 字幕生成 Video Subtitle Generator、字幕提取 Video Subtitle Extractor、字幕去除 Video Subtitle Remover),这两天部署了下,踩了些坑,记录一下解决方法。
首先按照 仓库 的 readme 文件去进行 下载安装 Miniconda、创建并激活虚机环境、安装依赖文件,这几步都没遇到什么问题。
fsplit 版本错误
然后在执行 'python gui.py' 进行运行图形化界面版本(GUI)时,报了 'No module named 'fsplit'' 的问题,这个库安装出错了,后面参考 issue 里面最后的 'pip install filesplit==3.0.2' 这个操作安装成功了,好像是原来默认下载的 fsplit 的库是 python2 的,不适配,换了 python3 的库就好了。
后面解决之后继续执行 'python gui.py' 运行图形化界面,后面打开视频是报错还有有些库没装上,然后通过 'pip install xxx' 手动一个个装上就可以了,另外可以在命令后加上 '-i https://pypi.tuna.tsinghua.edu.cn/simple' 加快安装速度。
推理跑在 CPU 上
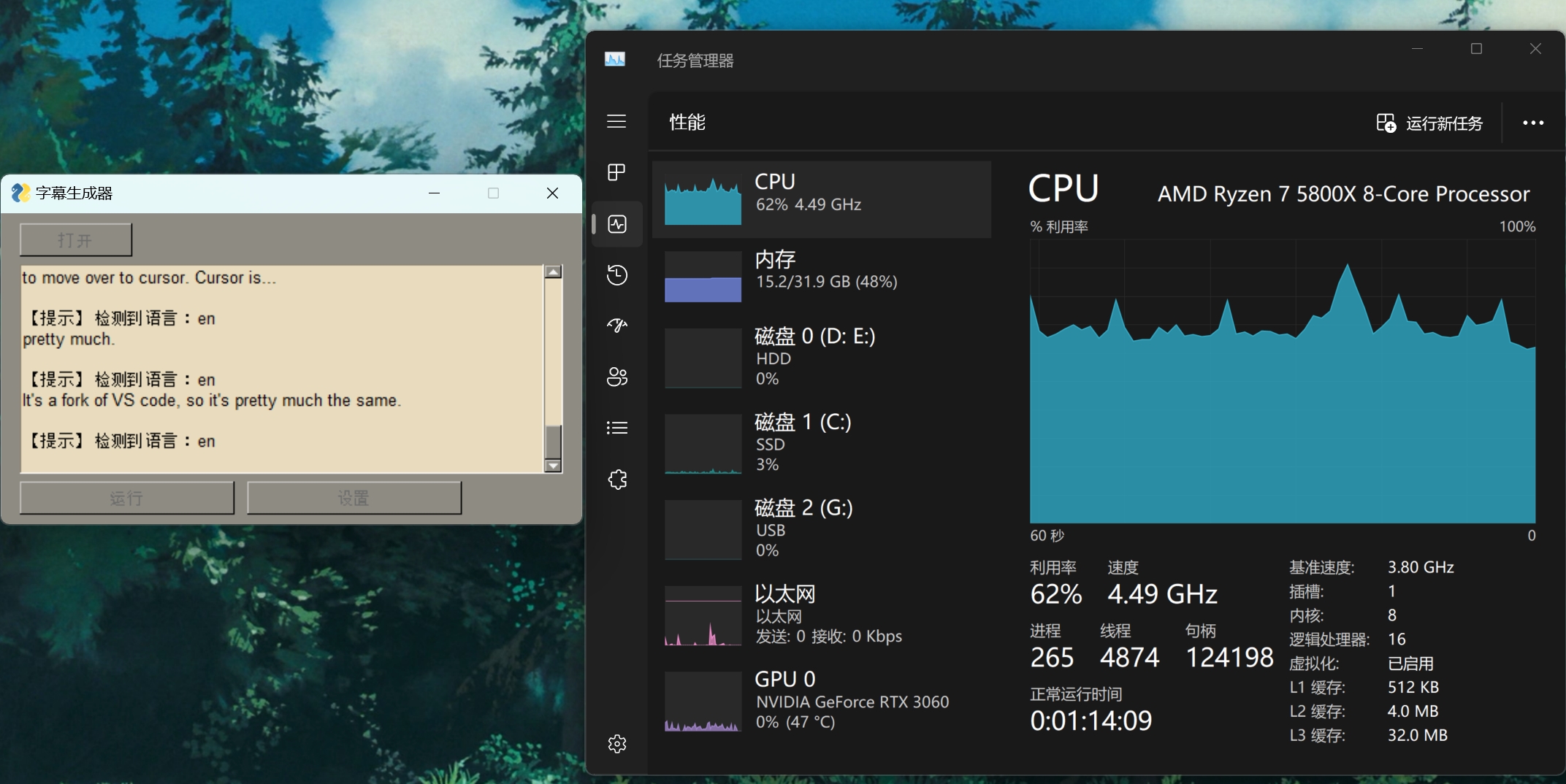 现在跑起来字幕生成,发现有显卡一动不动,CPU 占用特别高的情况,在 issue 链接里面看到别人好像也遇到了同样的 问题,一会我试试能不能解决。
现在跑起来字幕生成,发现有显卡一动不动,CPU 占用特别高的情况,在 issue 链接里面看到别人好像也遇到了同样的 问题,一会我试试能不能解决。
三条命令重装 torch ,但是好像解决不了问题。
pip uninstall torch
pip cache purge
pip install torch -f https://download.pytorch.org/whl/torch_stable.html
用 CPU 跑,12 分钟视频,300 行字幕,跑了 2779s。
(调完后用 GPU 同样跑 12 分钟视频,耗时 269s,快了 10 倍,找一天要了解下 CUDA 框架的原理。)
那个方法解决不了,现在试这个 方法 重新安装 CUDA 和 torch
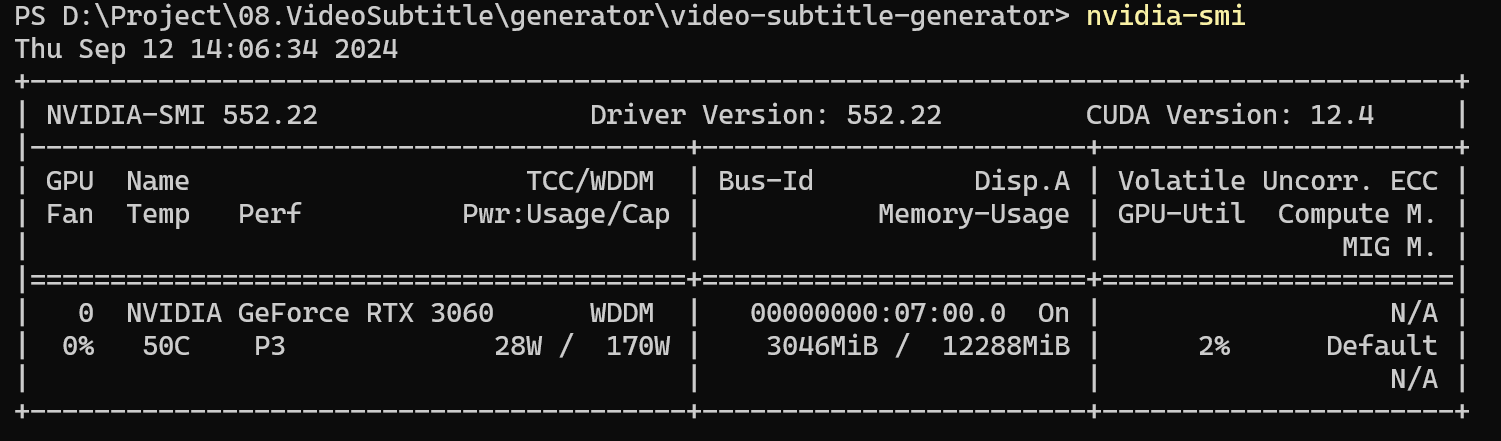
nvidia-smi 查看自己电脑支持 CUDA 的最高版本,(向下兼容?)
向下兼容,又称向后兼容(Backwards compatibility),计算机术语。向下兼容常常是相对于向上兼容而言的,两者在兼容的方向性上是相反的,因此这两个概念是不同的。向下兼容(Downward Compatibility),又称作向后兼容(Backward Compatibility)。在计算机中指在一个程序或者类库更新到较新的版本后,用旧的版本程序创建的文档或系统仍能被正常操作或使用,或在旧版本的类库的基础上开发的程序仍能正常编译运行的情况。例如较高档的计算机或较高版本的软件平台可以运行较为低档计算机或早期的软件平台所开发的程序,如基于Pentium微处理器的PC兼容机可以运行早期在486上运行的全部软件。向下兼容可以使用户在进行软件或硬件升级时,厂商不必为新设备或新平台从头开始编制应用程序,以前的程序在新的环境中任然有效。
CUDA 和 cuDNN 安装
nvidia-smi 查看显卡支持的 CUDA 版本。
CUDA 下载,安装选择 精简模式 即可。
cuDNN 下载,选择与 CUDA 对应的版本。
找到 CUDA 文件夹的地址,将 cuDNN 解压后的三个文件夹放进去。
添加环境变量(修改对应地址和版本)
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp
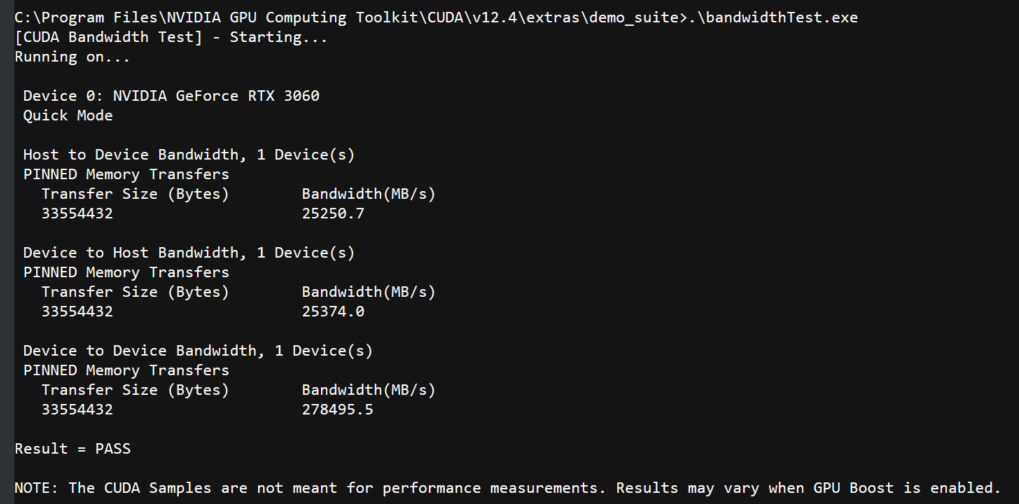
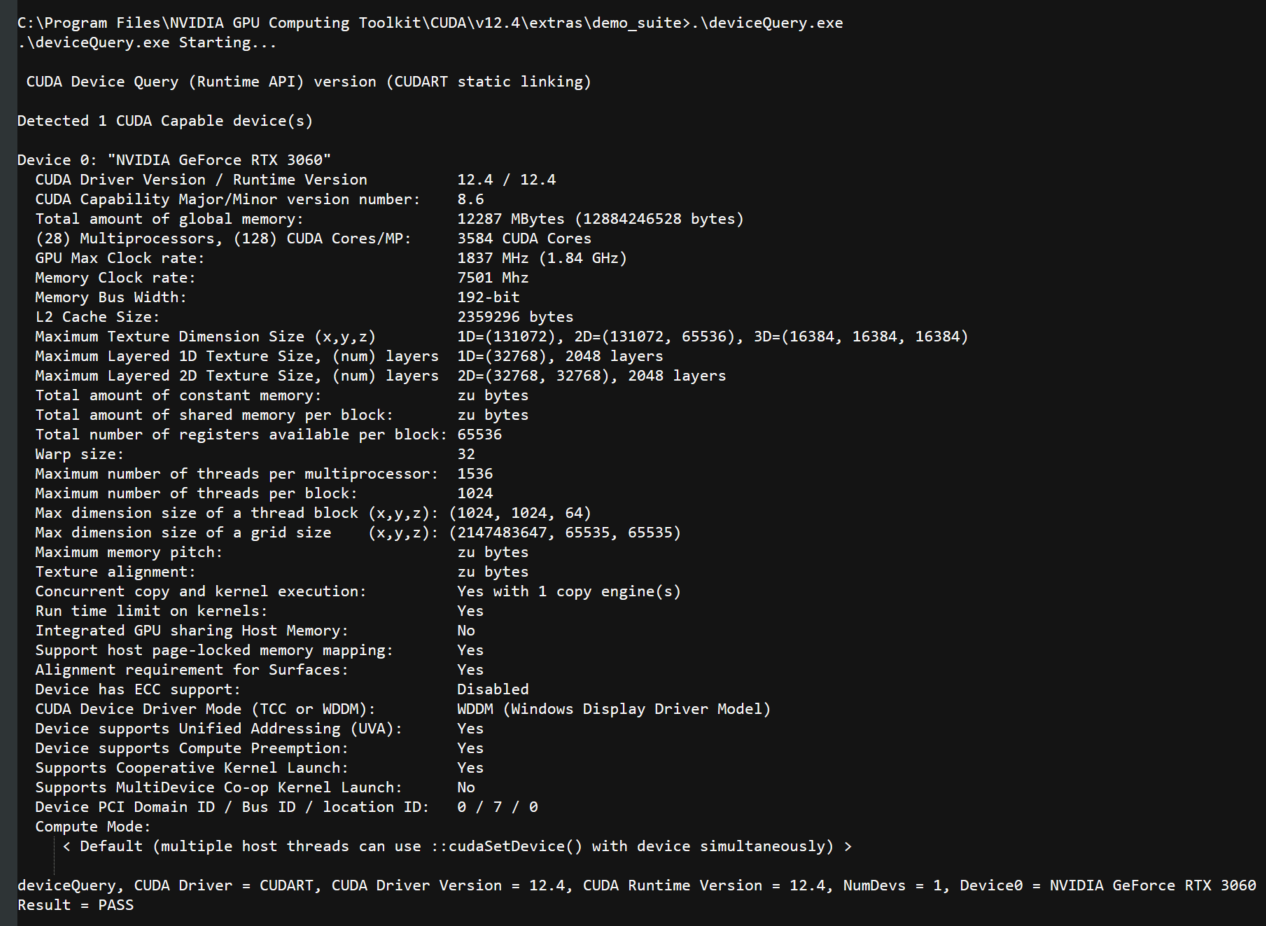
安装后使用 CUDA 内置的 deviceQuery.exe 和 bandwidthTest.exe 验证配置是否成功。 power shell 进入 CUDA 安装目录下的 ...\extras\demo_suite,后分别执行 deviceQuery.exe 和 bandwidthTest.exe ,出现相关显卡信息即配置成功。
torch 安装
pip install 的方式容易安装到 CPU 版本的,尽量选择下载 whl ,再通过 pip install torch* 进行安装。 一般要按 torch、torchaudio、torchvision 三件套,版本配套参考 这个链接 。 torch 对应 CUDA 版本、python 版本,whl 文件的含义参考以下。

paddle 安装
参考 官网链接,主要要选对和 CUDA 、cuDNN适配的版本,参考链接 ,若新的不支持,可以去安装 旧版本。
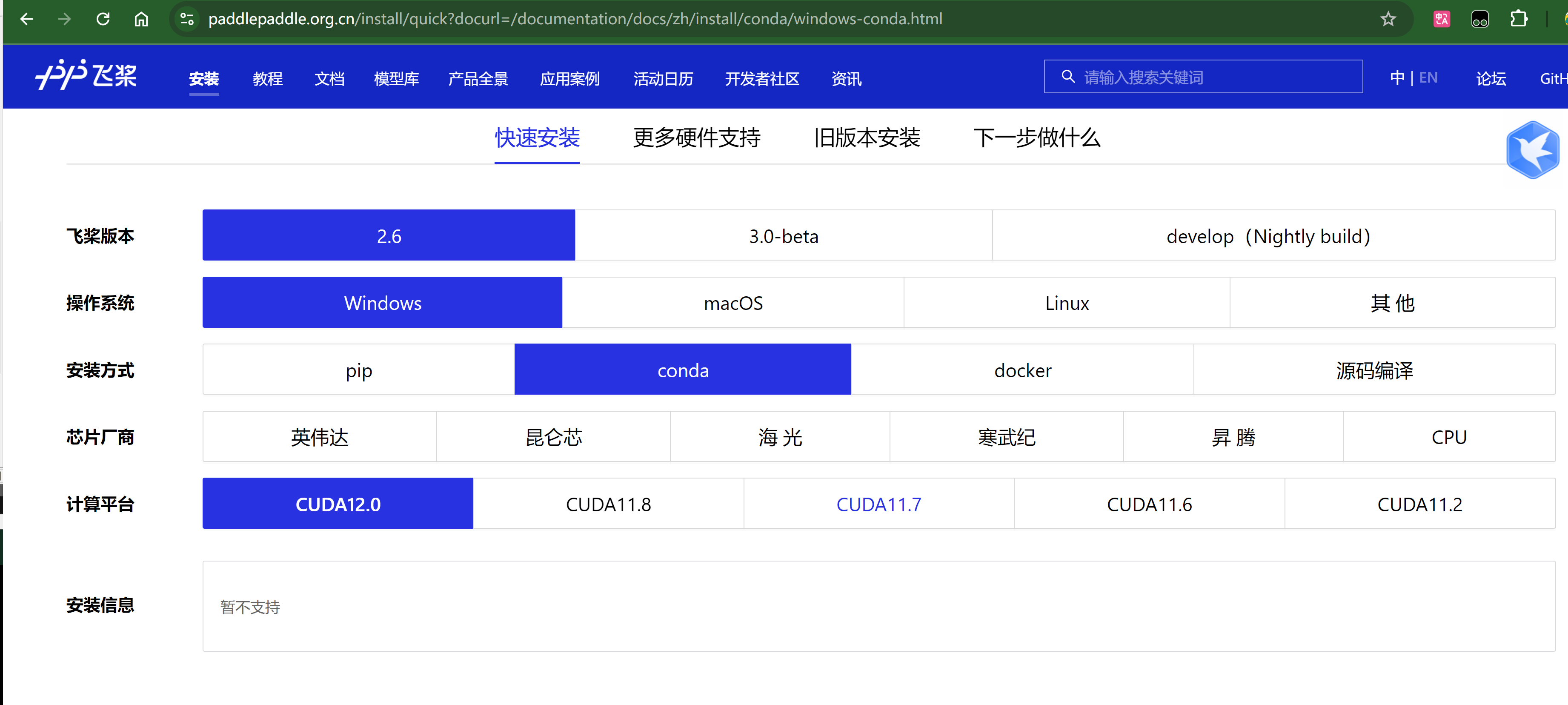
特殊情况
CUDA、cuDNN、torch、paddle,几个版本要适配。
本机 CUDA 使用12.4,可能太高了,paddle还不支持,现在下回项目使用的 11.7 版本的CUDA 。

解决库冲突
pip check 检查装的库有没有冲突。
冲突按照命令行里的提示处理,一般 pip uninstall xxx 删除某库,再 pip install XXX==版本号 安装某库,就可以解决大部分冲突。
warning 报错处理
运行出一些 warning 错误没啥影响。
而有个numpy的问题会影响,导致程序运行不下去。
module 'numpy' has no attribute 'int'. np.int was a deprecated alias for the builtin int. To avoid this error in existing code, use int by itself. Doing this will not modify any behavior and is safe. When replacing np.int, you may wish to use e.g. np.int64 or np.int32 to specify the precision. If you wish to review your current use, check the release note link for additional information.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
这个错误是由于 np.int 在 NumPy 1.20 中被弃用,并且在更新后的版本中完全移除了。为了修复这个问题并避免使用弃用的别名,你可以按照以下建议进行更改:
示例: 假设你原来的代码中有类似以下的代码片段:
python
Copy code
my_array = np.array([1, 2, 3], dtype=np.int)
你可以将它修改为:
python
Copy code
my_array = np.array([1, 2, 3], dtype=int) # 使用内置的 int
识别 GPU
Running Verify Fluid Program ...
W0913 07:35:22.368964 23832 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 12.4, Runtime API Version: 11.7
W0913 07:35:22.374960 23832 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Your Paddle Fluid works well on SINGLE GPU or CPU.
Your Paddle Fluid works well on MUTIPLE GPU or CPU.
Your Paddle Fluid is installed successfully! Let's start deep Learning with Paddle Fluid now
1536 864
为什么我的GPU没有被识别出来?
根据您提供的输出信息,您的GPU实际上已经被识别出来了。让我解释一下输出的含义:
-
GPU被识别:
W0913 07:35:22.368964 23832 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.6, Driver API Version: 12.4, Runtime API Version: 11.7这行表明系统检测到了一个GPU设备(device: 0),其计算能力为8.6。
-
cuDNN版本:
W0913 07:35:22.374960 23832 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.这表明CUDA深度神经网络库(cuDNN)版本8.2已被检测到。
-
GPU工作正常:
Your Paddle Fluid works well on SINGLE GPU or CPU. Your Paddle Fluid works well on MUTIPLE GPU or CPU.这些消息确认Paddle Fluid在单个和多个GPU上都能正常工作。
-
安装成功:
Your Paddle Fluid is installed successfully! Let's start deep Learning with Paddle Fluid now这表明Paddle Fluid已成功安装。
所以,您的GPU确实被正确识别和使用了。输出中的"W"表示这些是警告(Warning)消息,不是错误。这些警告通常用于提供额外信息,而不是表示问题。
至于您提到的"1536 864",这可能是指您的屏幕分辨率或者某个特定的参数设置,与GPU识别无关。
如果您在实际使用过程中遇到了GPU相关的问题,可能需要检查:
- CUDA和cuDNN的版本是否与您的Paddle版本兼容。
- 环境变量是否正确设置。
- 在Python代码中是否正确指定了使用GPU。
总的来说,根据提供的输出信息,您的GPU已经被正确识别和配置了。
代理引起的 pip install 错误
return ssl_context.wrap_socket(sock)
File "C:\Users\ghost\miniconda3\lib\ssl.py", line 500, in wrap_socket
return self.sslsocket_class._create
(File "C:\Users\ghost\miniconda3\lib\ssl.py", line 997, in _create
raise ValueError("check_hostname requires server_hostname"))
ValueError: check_hostname requires server_hostname
应该是开了代理,进行 pip install 遇到的错误,下次再遇到就问问 GPT 解掉。
总结
去搬别人仓库的工具使用:
一要看这个工具支持的环境,是不是适合自己,是不是只支持 N 卡;
二看这个仓库的维护情况,提的 issue 有没有及时解答,什么时候的项目,上一次 commit 是什么时候;
三看说明是否清晰,环境部署指引是否清晰,功能是否满足需求。
命令
pip install filesplit==3.0.2
pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install moviepy -i https://mirrors.aliyun.com/pypi/simple/
pip install moviepy -i https://pypi.doubanio.com/simple/
pip install moviepy -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install moviepy -i https://pypi.hustunique.com/simple/
pip install moviepy -i https://mirrors.163.com/pypi/simple/
nvidia-smi
pip uninstall torch
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip uninstall torch
pip cache purge
pip install torch -f https://download.pytorch.org/whl/torch_stable.html